Due to the non-stationary nature of the real-world environment, the data distribution could keep changing with continuous data streaming. Such a phenomenon/problem is called concept drift (Lu et al. 2018open in new window), where the basic assumption is that concept drift happens unexpectedly and is unpredictable for streaming data.
To handle concept drift, previous studies usually leverage a two-step approach.
Detect the concept drift.
Adapt the model to the new data distribution.
Retrain the model
Fine-tune the model
Assumption
The latest data contains more useful information than the previous data.
Existing methods handle concept drift on the latest arrived data Data(t) at timestamp t and adapt the forecasting model accordingly. The concept drift continues, and the adapted model on Data(t) will be used on unseen streaming data in the future (e.g., Data(t+1)). The previous model adaptation has a one-step delay to the concept drift of upcoming streaming data, which means a new concept drift has occurred between timestamp t and t+1.
In this paper, we focus on predictable concept drift by forecasting future data distribution.
where each element x(t)∈Rm is a m-dimensional vector.
x(t)=[x1(t),x2(t),⋯,xm(t)]
Given a target sequence y={y(1),y(2),⋯,y(T)} corresponding to X.
Algorithm are designed to build the model on historical data {x(i),y(i)}i=1t and predict the future data x(t) and forecast y on unseen streaming data Dtest(t)={x(t),y(t)}t=1T.
Assume (x(t),y(t))∼pt(x,y), where pt(x,y) is the data distribution at timestamp t. Generally, pt(x,y) is non-stationary and keeps changing with time t, which is called concept drift. Formally, the concept drift between two timestamps t and t+1 can be defined as
∃x:pt(x,y)=pt+1(x,y)
Adapting models to accommodate the evolving data distribution.
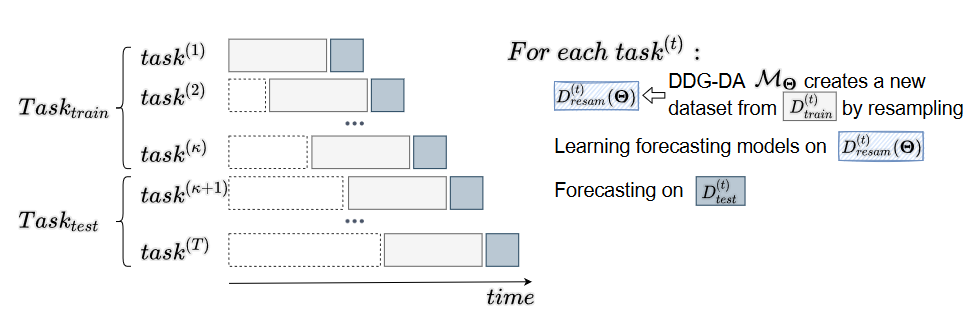
Given task(t)∈Tasktest, the forecast model is trained on Dresam(t)(Θ) and forcast on Dtest(t).
presam(t)(x,y;Θ) is more similar to ptest(t)(x,y) than ptrain(t)(x,y). So the preference of model f(t) on Dresam(t)(Θ) is more similar to f(t) on Dtest(t) than f(t) on Dtrain(t).
Example
To handle the concept drift in data, we retrain a new model each month (the rolling time interval is 1 month) based on two years of historical data.
Each chance to retrain a new model to adapt the concept drift is called a task. For example, the task task(2011/01) contains Dtrain(2011/01) from 2009/01 to 2010/12 and Dtest(2011/01) in 2011/01.
Set all Dtest(t) range from 2011 to 2015 and DDG-DA will evaluated on Tasktest range from 2016 to 2020.
where DKL is the KL divergence. ∣∣ is the divergence between two distributions. Ex∼ptest(t)(x) is the expectation over the test data distribution ptest(t)(x).
Normal distribution assumption is reasonable for unknown variables and often used in maximum likelihood estimation. So we assume ptest(t)(y∣x) and presam(t)(y∣x;Θ) are normal distributions.
ptest(t)(y∣x)=N(ytest(t)(x),σ)
presam(t)(y∣x;Θ)=N(yresam(t)(x;Θ),σ)
Tips
yresam(t)(x;Θ) is the expectation of y under the predicted distribution presam(t)(y∣x;Θ).
According to the definition of KL divergence, we have